My software
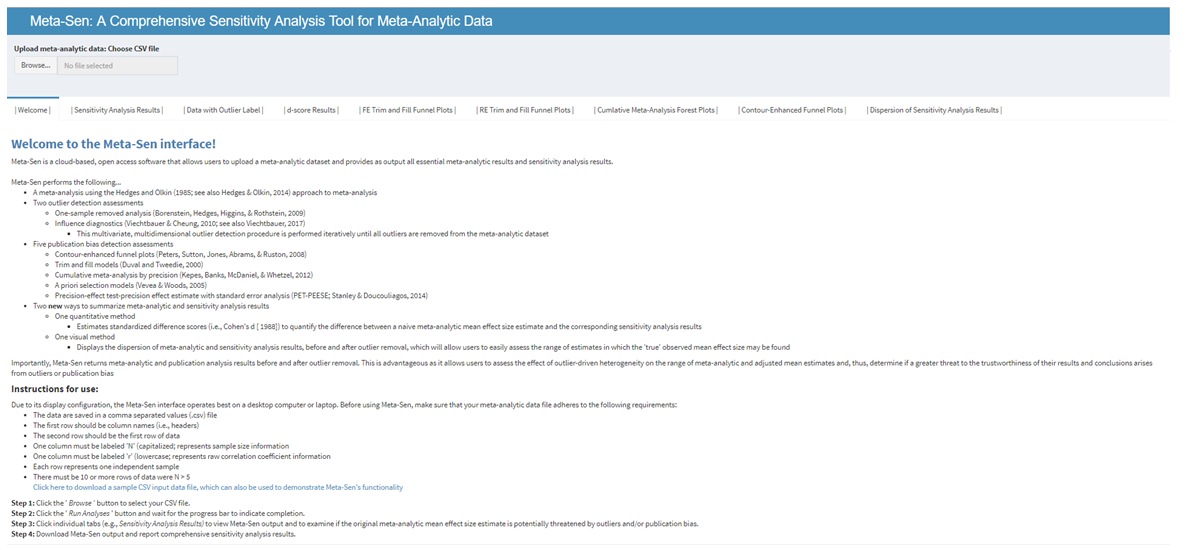
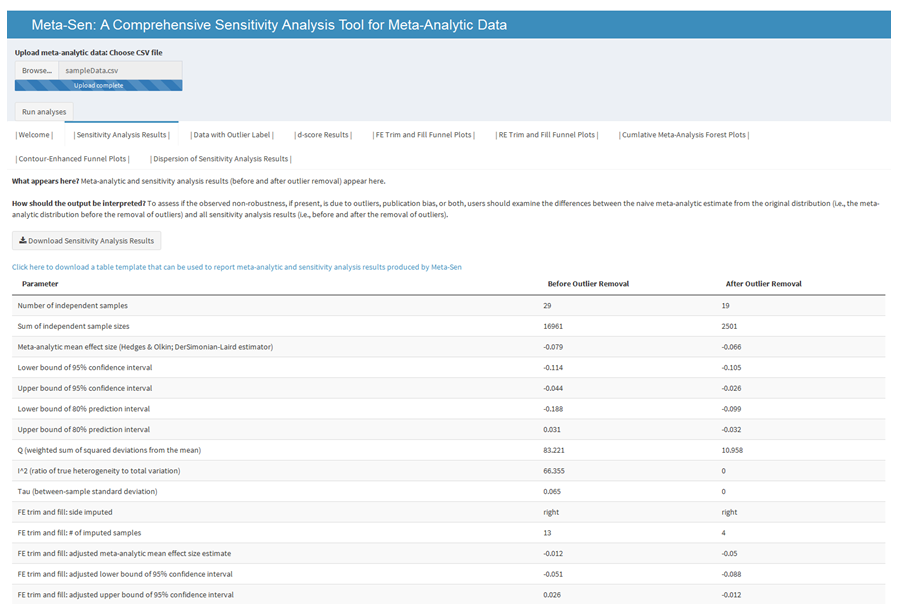
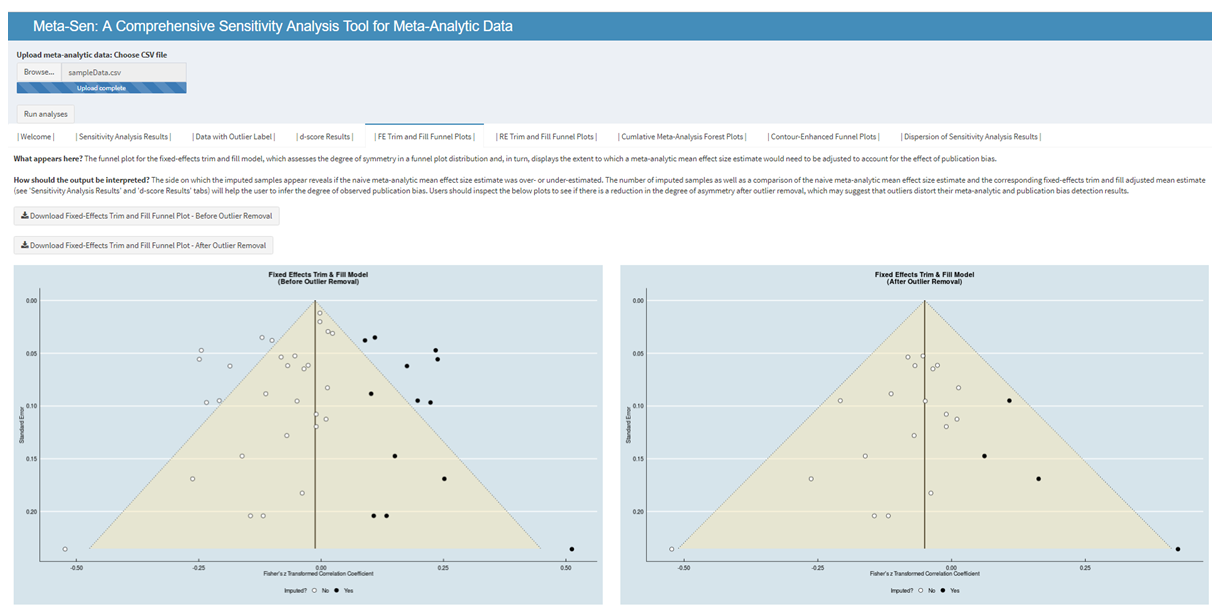
Meta-Sen
Meta-analytic reviews are the primary means for generating cumulative knowledge and their results are often used to inform evidence-based practice. Although recent research indicates that outliers and publication bias can distort meta-analytic results, analyses are rarely conducted to assess their independent effects. Moreover, analyses that account for the combined effect of these phenomena are almost completely nonexistent. Consequently, the potential non-robustness of meta-analytic results often goes undetected, which brings into question the trustworthiness of our cumulative knowledge. I (along with help from Dr. Frank Bosco) developed a Shiny interface, called metaSen, that will facilitate the conduct of meta-analyses that adhere to recommended reporting standards and best practices. Specifically, this open access software allows users to upload a meta-analytic dataset and provides as output essential meta-analytic and sensitivity analysis results.
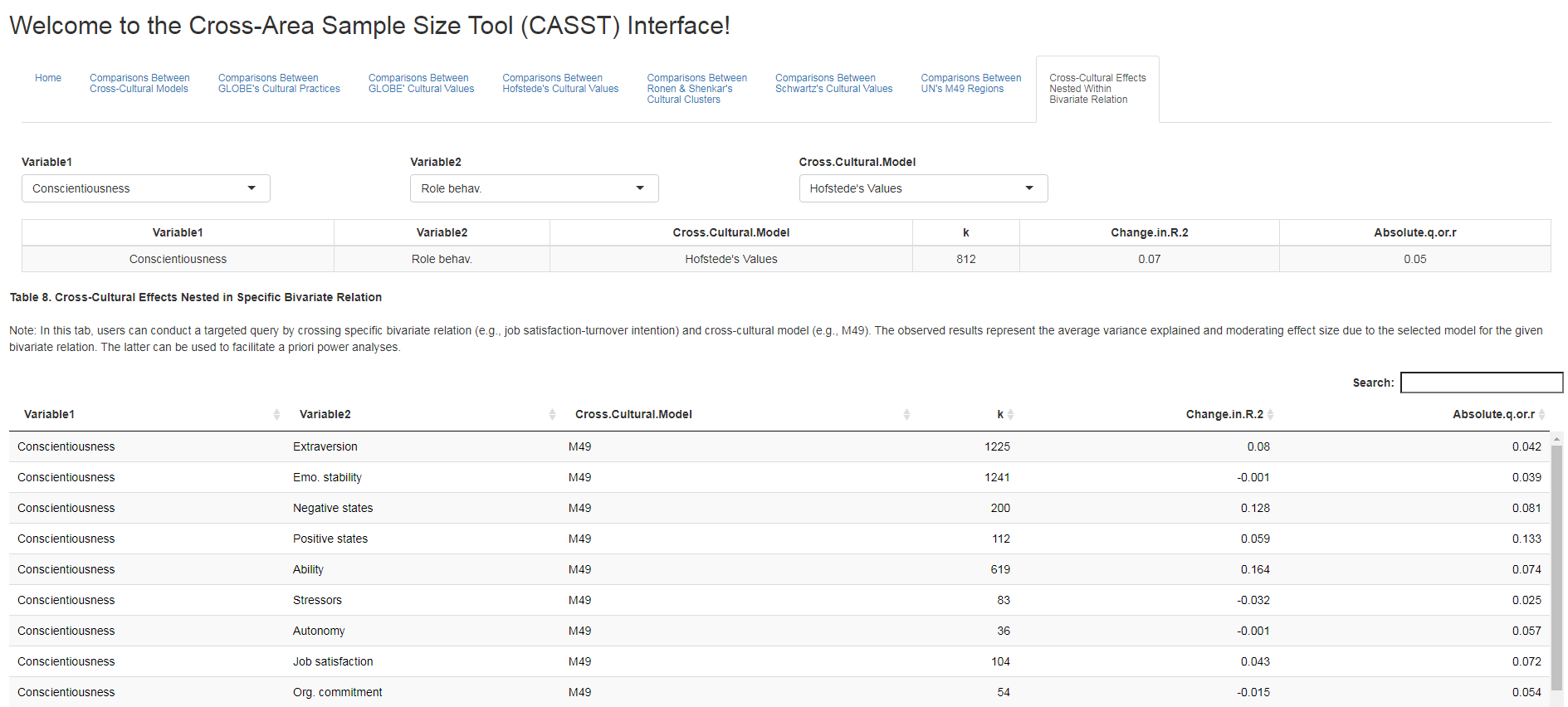
Relatively little is known about the extent to which culture moderates findings in applied psychology research. In our paper published in the Journal of International Business Studies we leveraged the metaBUS database of over 1,000,000 published findings to examine the extent to which six popular cross-cultural models explain variance in findings across 136 bivariate relations and 56 individual cultural dimensions. We compared moderating effects attributable to Hofstede’s dimensions, GLOBE’s practices, GLOBE’s values, Schwartz’s Value Survey, Ronen & Shenkar’s cultural clusters, and the United Nations’ M49 standard. Results from 25,296 multilevel meta-analyses indicate that, after accounting for statistical artifacts, cross-cultural models explain approximately 5-7% of the variance in findings. In our paper we introduced a web-based software called CASST (Cross-Area Sample Size Tool; see ) that allows users to interact with our results and can be used by future cross-cultural researchers to aid with a priori sample size estimation.

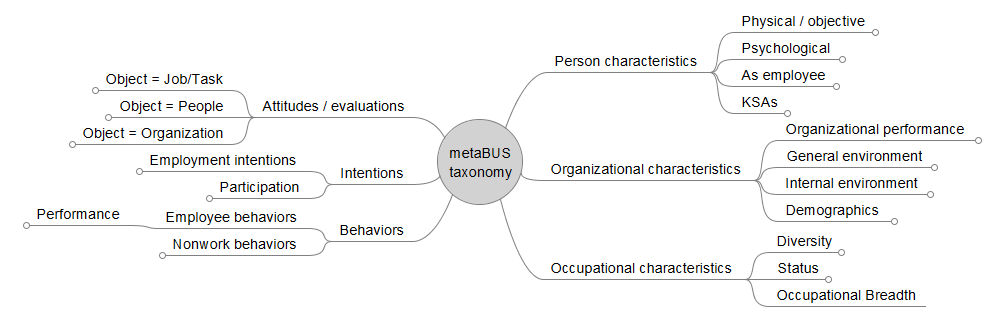
Since 2011 I have contributed to metaBUS project, an international program that has received approximately $1 million in funding from agencies like the National Science Foundation and the Society for Human Resource Management (SHRM) Foundation. The metaBUS project aims to curate and disseminate volumes of scientific research, thereby making it easier to quantify and visualize answers to big science questions. Currently, the metaBUS database is made up of more than 1.1 million correlation coefficients and corresponding meta-data (e.g., sample size, reliability coefficient), which have been extracted from approximately 15,000 articles published in more than 25 OB/HR journals since 1980. Importantly, each correlation coefficient is tagged to a hierarchical taxonomy of 4,869 variables reported in the scientific space of applied psychology (Bosco, Aguinis, Singh, Field, & Pierce, 2015). The taxonomy arranges variables into broad branches (e.g., attitudes; behaviors) and then into finer levels of granularity. For example, the taxonomic path to arrive at overall job satisfaction is “attitudes→job attitudes→general job affect→positive→job satisfaction.” The utility of this approach is that, in addition to specific, targeted queries, it permits very broad queries. For example, one may query the database to assess the meta-analytic mean effect size estimate for the "job satisfaction-job performance" relation (i.e., targeted query) or all “attitude-behavior” relations (i.e., broad query).